Guidelines for iKAT 2026 Year 4
- The guidelines for iKAT 2024 (year 2) are available as a Google Doc.
- The guidelines for iKAT 2023 (year 1) are available as a Google Doc.
Motivation
The Interactive Knowledge Assistance Track (iKAT) aims to advance research on collaborative information-seeking conversational agents that generate personalized responses by leveraging information learned about the user.
In iKAT, given the same topic, users with different personas may follow distinct conversational paths, which affects which system responses are deemed acceptable for the same underlying information need. With the advent of large language models (LLMs), this task is especially timely—raising new challenges in integrating personalization through context-aware prompting, dynamic interaction, and mixed-initiative dialogue. In addition, iKAT explores a simulation-based evaluation methodology to advance research on modeling different users and their associated behaviors.
Track Overview
In iKAT, the next turn of a conversation is influenced by the following aspects.
- The previous responses from the system and utterances from the user.
- The persona of the user.
- The information revealed by the user during the conversation (background, perspective, previous conversations, and context).
Each user is assigned a distinct persona and will engage in multiple conversations across different topics. The persona and the information needs of the user are modeled by generating a Personal Textual Knowledge Base (PTKB), which is available to the system during the conversation to simulate information the system gained on the user in previous conversations.
What’s New?
- Modelling of diverse search behavior: In year 4, iKAT employs simulated users that implement diverse search behaviors (e.g., language skills, cooperativeness, patience), while having exactly the same information need. Participating systems should be robust in the sense that they assist every user to satisfy their information needs.
- Interactive-only submissions: This year, we only accept interactive submissions where the participant systems will interact with simulated users through an online API.
Task Overview
Participants of iKAT will receive the following resources to provide their run submissions.
- Test dataset of prior iKAT editions that contains the following information:
- Topics
- Example conversations
- Personal Text Knowledge Bases (PTKB) of the users
- Passage collection (ClueWeb22-B)
- Access to the user simulation API (Sim.API) and documentation.
Task: For each real-time simulated user turn, retrieve and rank relevant passages from the passage collection. Then use the ranked passages to generate a personalized response based on the user’s PTKB, user utterance, and context. This response is passed back to the simulated user, which again produces an utterance. This process is repeated until the user terminates the conversation. Along with the generated text response, the systems have to provide the ranked list of passages (citations), and the PTKB statements that were deemed relevant for each produced turn.
Example Dialogue Tree
An example of two different conversations based on different personas for the same topic is shown in the following figure. For each user turn, systems should return a text response. Each response has one or more (ranked) source passages as provenance. In addition, the systems should provide a list of relevant statements of PTKB with the corresponding relevance score, sorted by this score.
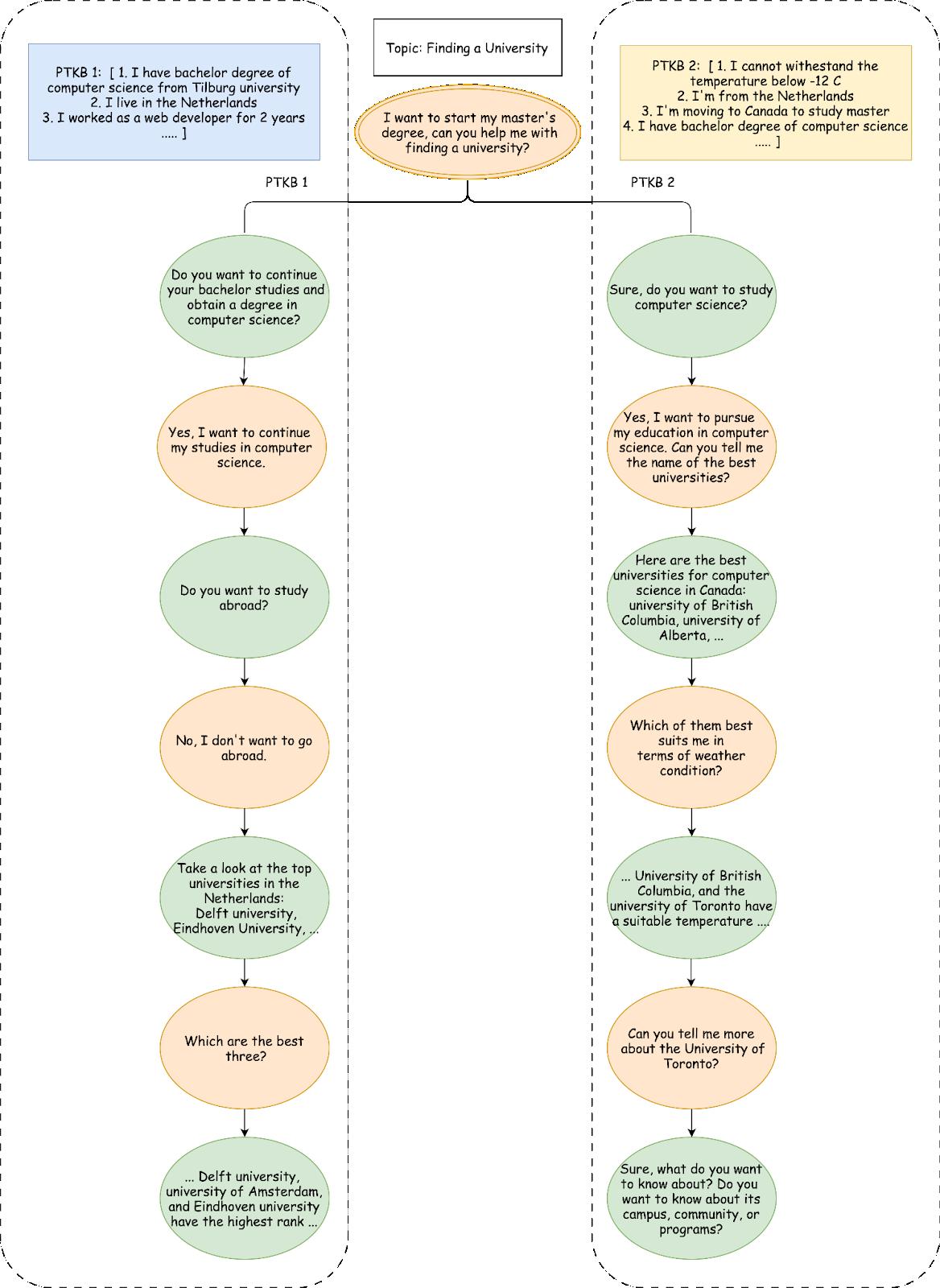
Below, we provide a detailed explanation of the above diagram.
| Turn | Field | Value |
|---|---|---|
| Topic 1-1, PTKB_1 | ||
| 1 | User utterance | I want to start my master’s degree, can you help me with finding a university? |
| Response | Do you want to continue your bachelor’s studies and obtain a degree in computer science? | |
| Citations | Null | |
| Relevant PTKBs |
|
|
| 2 | User utterance | Yes, I want to continue my studies in computer science. |
| Response | Do you want to study abroad? | |
| Citations | Null | |
| Relevant PTKBs |
|
|
| 3 | User utterance | No, I don't want to go abroad. |
| Response |
I can help you find a university to continue your studies in the Netherlands as a computer science student. Take a look at these Top Computer Science Universities in the Netherlands:
|
|
| Citations | clueweb22-en0034-09-03452:0 | |
| Relevant PTKBs |
|
|
| 4 | User utterance | Which are the best three? |
| Response |
Based on the ranking of research.com the top three universities are as follows:
|
|
| Citations | clueweb22-en0016-21-09213:0 | |
| Relevant PTKBs |
|
|
| Topic 1-2, PTKB_2 | ||
| 1 | User utterance | I want to start my master’s degree, can you help me with finding a university? |
| Response | Sure, do you want to study computer science? | |
| Citations | Null | |
| Relevant PTKBs |
|
|
| 2 | User utterance | Yes, I want to pursue my education in computer science. Can you tell me the names of the best universities? |
| Response |
Here are the best universities for computer science in Canada:
|
|
| Citations | clueweb22-en0026-31-15538:1 clueweb22-en0026-31-15538:4 clueweb22-en0026-31-15538:6 clueweb22-en0040-41-06056:0 |
|
| Relevant PTKBs |
|
|
| 3 | User utterance | Which of them best suits me in terms of weather conditions? |
| Response |
University of British Columbia in Vancouver has temperatures near 80 degrees Fahrenheit (27 degrees Celsius) in summer and up to 45 degrees Fahrenheit (about 7 degrees Celsius) in winter which is suitable for you. The University of Toronto is acceptable since it has cold winters, average temperatures can drop below -10 ° C but not below 12 degrees for long. The Concordia University in Montreal is not suitable for you since in the winter, it could reach minus 40 with the wind chill. The University of Alberta is also not suitable for you. In winter the average temperature varies between -6.5°C (20.3°F) and -13.5°C (7.7°F). Simon Fraser University is not acceptable to you. The city in which the university is located will reach temperatures of -14 in the winter. |
|
| Citations | clueweb22-en0000-94-02275:0 clueweb22-en0027-06-08704:1 clueweb22-en0005-63-12144:0 clueweb22-en0013-01-17558:1 clueweb22-en0014-39-04143:0 |
|
| Relevant PTKBs |
|
|
| 4 | User utterance | Can you tell me more about the University of Toronto? |
| Response | Sure, what do you want to know about? Do you want to know about its campus, community, or programs? | |
| Citations | Null | |
| Relevant PTKBs | Null | |
PTKB Statement Classification and Extraction
- This task can be understood as a binary classification problem. The output is a list of the statements from PTKB that are relevant for responding to the user’s utterance.
- The provenance PTKB statements can be an empty list for some responses.
- The PTKB statements can be taken from the given list of PTKB statements, or extracted from previous user conversations.
- New PTKB statements can be extracted from the previous conversations and mentioned in the list of relevant PTKB statements.
Passage Ranking (citation)
- A run should include relevant passages retrieved by the retrieval model (called “citations” in the submission format) for most turns of the conversation.
- If the turn’s action is not an answer (e.g., clarifying questions), the “citations” field can be left empty, as shown in the example above.
- The “citations” field is a list of the max. top 10 passages retrieved by the retrieval model based on their relevance. The passages must be provided as doc_id:passage_id.
- The top 10 relevant passages for each turn will be assessed.
Response Generation
- Responses can be generated from multiple passages. Responses can be an abstractive or extractive summary of the corresponding passages, or a text generated by a retrieval-augment generation (RAG) approach.
- A response is a text suitable for showing to a user. It should be fluent, satisfy their information needs, and not contain extraneous or redundant information. Clarifying or elicitation questions (or other mixed-initiative strategies) are encouraged.
- A response is limited to a maximum of 512 tokens (as measured by the
Tokenizerfunction ofspacy.tokenizerin spaCy v3.3 library).
Interactive Run Submission
- Conversations in this task are always initiated by the simulated user. On submitting run meta information to the simulation API, participants receive the first user utterance.
- Participant systems should retrieve relevant passages from the collection based on the utterance and generate a response. The ranked list of passages and the generated response should be sent back to the simulation API.
- On sending back the passages and the response results, participants receive a new user utterance from the API.
- This process is repeated until the user indicates (through a flag, last_response_of_session) that they terminate the current session.
- The next request of a participant system then leads to a user utterance for a new session on a new topic with a (potential) new user.
- This process is repeated until all topics in the test set have been addressed, which will also be indicated through a flag in the API.
- After all topics have been addressed, the run counts as submitted (no additional submission of a run file required).
- Responses from the simulation API contain identifiers to differentiate with which user the participants' system currently talks with. This allows participants to track persona statements of reoccurring users. If participants track persona statements they can provide relevant statements through the API as well.
- This task invites participants to apply various techniques to clarify information needs like asking clarifying questions or preference elicitation. However, attempts at jailbreaking to reveal PTKBs or other system details will result in disqualification.
Technical documentation on how to operate Sim.API can be found here. A sample interaction with Sim.API can be found below.
API Output Example
{
"timestamp":"2025-05-06T10:58:33.400920",
"run_id":"teamA-llama3-dense-retrieval",
"topic_id":"1-1",
"user_id":"f3333f5c-8313-4941-beea-f24de25a583a",
"utterance":"Show me universities with computer science programs.",
"history":[
{"role":"user","content":"Show me universities with computer science programs."}
],
"last_response_of_session":false,
"last_response_of_run":false,
"user_meta": {
"ptkb": [
"I have a Bachelor's degree in computer science."
"..."
]
}
}
API Input Example
{
"run_id": "teamA-llama3-dense-retrieval",
"response": "There is University of Amsterdam.",
"citations": {
"clueweb22-en0032-04-00208:7": 0.8,
"clueweb22-en0027-84-11778:0": 0.4
},
"meta": {
"ptkb_provenance": [
"I live in the Netherlands."
]
}
}
User Simulators
Participant systems will interact with a secret set of user simulator implementations. In particular, this year will focus on modeling aspects that contribute to diverse search behaviors. An attribute that comes to mind is, for example, language proficiency and the ability to articulate a query for an information need. As a result, queries might be vague and ambiguous. Another example of such a property is a user’s patience, who could produce emotionally loaded responses whenever his information need is not immediately satisfied. The goal for the participant’s systems is to help each user satisfy their information need independently of how uncooperative their behaviors might seem.
Collection
The text collection contains a subset of ClueWeb22 documents, prepared by the organizers in collaboration with CMU. Documents have been split into ~116M passages. The goal is to retrieve passages from target open-domain text collections.
License for ClueWeb22-B
Getting the license to use the collection can be time-consuming and would be handled by CMU, not the iKAT organizers. Please follow these steps to get your data license ASAP:
- Sign the license form available on the ClueWeb22 project web page and send the form to CMU for approval (clueweb@andrew.cmu.edu).
- TBA.
Instructions on how to download the collection follow ASAP.
Please give enough time to the CMU licensing office to accept your request.
Note. - CMU requires a signature from the organization (i.e., the university or company), not an individual who wants to use the data. This can slow down the process at your end too. So, it’s useful to start the process ASAP. - If you already have an accepted license for ClueWeb22, you do not need a new form. Please let us know if that is the case. - As an alternative for (2), once you have access to ClueWeb22, you can get the raw ClueWeb22-B/iKAT collection yourself with the license, and do all passage-segmentation yourself, but we advise you to use our processed version to avoid any error.
Please do feel free to reach out to us if you have any questions or doubts about the process, so we can prevent any delays in getting the data to you.
Provided ClueWeb22 Indices
As of now, our resource includes a BM25 Pyserini index of the collection, and a SPLADE index of the collection.
The SPLADE index was made with the numba library, as in the original SPLADE github, and can be re-used for retrieval. It uses the SPLADE++ model.
Topics
We will provide several sample topics with example baseline runs for validation and testing from prior iKAT editions. Below is a sample topics file from two different personas on the same topic. The conv_id represents a concatenation of the persona and topic id <persona_id>-<topic_id>. Also, a citation field with a list of provenance passages and a ptkb_provenance field with a list of provenance statements from PTKB are included. These two fields define the trajectory of the conversation and should be used for generating responses in the offline response generation task.
[
{
"conv_id": "1-1",
"title": "Finding a University",
"ptkb": [
"I graduated from Tilburg University.",
"I live in the Netherlands.",
"I'm allergic to peanuts.",
"I worked as a web developer for 2 years.",
"I have a bachelor's degree in computer science.",
"I like Indian food.",
"My bachelor's GPA is 5.6.",
"I'm 26 years old.",
"My TOEFL SCORE is 91.",
"My interesting bachelor courses are data structure, algorithm, data mining, and artificial intelligence.",
"I didn't like computer architecture and logical circuits courses."
],
"responses": [
{
"turn_id": 1,
"user_utterance": "I want to start my master's degree, can you help me with finding a university?",
"resolved_utterance": "I want to start my master's degree, can you help me with finding a university?",
"response": "Do you want to continue your bachelor's studies and obtain a degree in computer science?",
"ptkb_provenance": [
"I have a bachelor's degree in computer science."
],
"citations": [
"clueweb22-en0034-09-03452:1",
"clueweb22-en0034-09-03452:3",
"clueweb22-en0034-09-03452:5",
"clueweb22-en0034-09-03452:7",
"clueweb22-en0034-09-03452:9"
]
},
{
"turn_id": 2,
"user_utterance": "Yes, I want to continue my studies in computer science.",
"resolved_utterance": "Yes, I want to continue my studies in computer science.",
"response": "Do you want to study in the Netherlands, Europe, or somewhere further away?",
"ptkb_provenance": [
"I live in the Netherlands."
],
"citations": [
"clueweb22-en0034-09-03452:2",
"clueweb22-en0034-09-03452:4",
"clueweb22-en0034-09-03452:6",
"clueweb22-en0034-09-03452:8",
"clueweb22-en0034-09-03452:10"
]
},
{
"turn_id": 3,
"user_utterance": "I'd like to stay here.",
"resolved_utterance": "I'd like to stay in the Netherlands.",
"response": "I can help you with finding a university for continuing your studies in the Netherlands as a computer science student. Take a look at these Top Computer Science Universities in the Netherlands: Delft University of Technology, Eindhoven University of Technology, Vrije Universiteit Amsterdam, University of Amsterdam, Leiden University, Radboud University, Utrecht University, University of Twente",
"ptkb_provenance": [
"I have a bachelor's degree in computer science.",
"I live in the Netherlands."
],
"citattions": [
"clueweb22-en0012-00-00012:0",
"clueweb22-en0012-00-00012:1",
"clueweb22-en0012-00-00012:2",
"clueweb22-en0012-00-00012:3",
"clueweb22-en0012-00-00012:4"
]
}
]
},
{
"conv_id": "2-2",
"title": "Finding a university",
"ptkb": [
"I don't like crazy cold weather.",
"I don't have a driver's license.",
"I plan to move to Canada.",
"I'm from the Netherlands.",
"I'm used to heavy rains in the Netherlands.",
"I graduated from UvA.",
"I have bachelor's degree in computer science.",
"I speak English fluently."
],
"responses": [
{
"turn_id": 1,
"user_utterance": "I want to start my master's degree, can you help me with finding a university?",
"resolved_utterance": "I want to start my master's degree, can you help me with finding a university in Canada?",
"response": "Sure, do you want to study computer science?",
"ptkb_provenance": [
"I have bachelor's degree in computer science.",
"I plan to move to Canada."
],
"citations": [
"clueweb22-en0040-41-06056:0",
"clueweb22-en0040-41-06056:1",
"clueweb22-en0040-41-06056:2",
"clueweb22-en0040-41-06056:3",
"clueweb22-en0040-41-06056:4"
]
},
{
"turn_id": 2,
"user_utterance": "Yes, I want to pursue the same major. Can you tell me the name of the best universities?",
"resolved_utterance": "Yes, I want to pursue computer science. Can you tell me the name of the best computer science universities in Canada?",
"response": "Here are the top universities for computer science in Canada: 1) University of British Columbia, 2) University of Alberta, 3) Concordia University, 4) Simon Fraser University, 5) The University of Toronto",
"ptkb_provenance": [],
"citations": [
"clueweb22-en0026-31-15538:1",
"clueweb22-en0026-31-15538:4",
"clueweb22-en0026-31-15538:6",
"clueweb22-en0040-41-06056:0"
]
},
{
"turn_id": 3,
"user_utterance": "Which of them best suits me in terms of weather conditions?",
"resolved_utterance": "Which of the following universities best suits me in terms of weather conditions? 1) the University of British Columbia, 2) the University of Alberta, 3) Concordia University, 4) Simon Fraser University, and 5) The University of Toronto.",
"response": "I know you don't like very cold weather, but can you give me an estimation of the temperature that is acceptable for you?",
"ptkb_provenance": [
"I don't like crazy cold weather.",
"I'm used to heavy rains in the Netherlands."
],
"citations": [
"clueweb22-en0030-30-30030:0",
"clueweb22-en0030-30-30030:1",
"clueweb22-en0030-30-30030:2",
"clueweb22-en0030-30-30030:3",
"clueweb22-en0030-30-30030:4"
]
}
]
}
]
Task Submissions
Submissions to iKAT will be done via the user simulation API (Sim.API). Please refer to the technical documentation for more details on the submission process.
Evaluation
We will use the relevance assessment methods used in the previous year of iKAT 2023 for relevance to individual turns.
- Citations Assessment: The cited passages that are used to produce the responses will be pooled and assessed. The relevance scale will be the same as in previous years of iKAT, see the previous overview papers for details. The standard ranking metrics such as P@k, NDCG@k, and MAP will be calculated using the judgments. We will focus on the earlier positions (1, 3, 5).
- Extracted Relevant PTKB Statements Assessment: The standard metrics like Precision, Recall, and F1 will be used for evaluating the identified list of relevant statements from PTKB. We will assess both pre-defined and newly extracted PTKB statements by the teams.
- Response Assessment: Submitted responses will be evaluated by a mixture of LLM-as-a-judge and human annotations on standard criteria (e.g., relevance, coherence). Additionally, nugget based evaluation metrics will be considered for the evaluation of responses as well.
- Dialogue-level Assessment: We will assess the whole dialogue and the trajectory. Given the flexible nature of the simulated dialogues, we will devise dialogue-level metrics that take into account the system’s capabilities to provide useful information to the users in the dialogue as a whole. These could be based on ideas such as “last-bot-standing”, or returning the most nuggets in the same time budget. More details will follow later.
Similar to the past years of iKAT, only a subset of turns may be evaluated for provenance ranking effectiveness and response generation quality. This will be disclosed to participants only after the assessment is completed.
Related Resources
Below are some useful code resources related to TREC iKAT.
- Official TREC iKAT Organizer GitHub:
- Related code and baselines: